



Introduction
In the face of increasing digital complexity and market demands, large-scale enterprises are turning to DevOps to enhance agility, accelerate delivery, and improve system reliability. While DevOps practices have proven effective for smaller teams, scaling these practices across large, complex enterprises introduces unique challenges. This white paper explores the core challenges of scaling DevOps, identifies proven solutions, and outlines best practices to enable high-performance DevOps teams.
1. Understanding the Challenges of Scaling DevOps
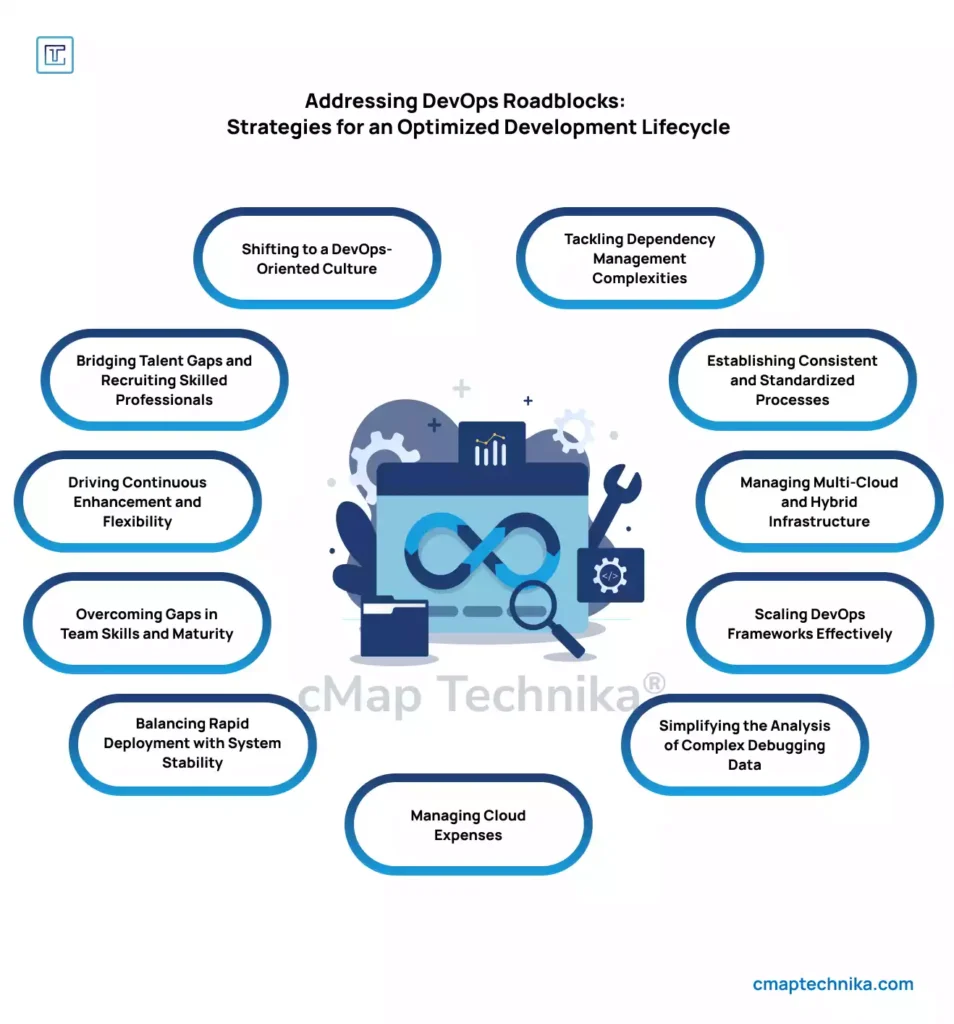
As organizations grow, the complexity of managing development and operations at scale increases. Key challenges include:
a. Fragmented Tooling and Processes
Enterprises often have multiple teams using different tools and workflows, leading to inefficiencies and misalignment. Without standardized tooling and processes, it becomes difficult to achieve consistent performance across teams.
Example: A global financial services company experienced delays in product releases because development teams used different CI/CD pipelines, creating compatibility issues during integration.
b. Organizational Silos and Lack of Communication
In large organizations, development, operations, and security teams often work in isolation, resulting in misaligned goals and slow feedback loops.
Example: A Fortune 500 retailer struggled to reduce deployment times because developers and operations teams followed separate release schedules, causing deployment conflicts and downtime.
c. Scaling Infrastructure Efficiently
As application workloads increase, infrastructure must scale rapidly to meet demand without compromising performance or cost efficiency. Manual scaling methods become unsustainable at the enterprise level.
Example: A major e-commerce platform experienced performance bottlenecks during peak seasons due to inadequate infrastructure automation, leading to lost sales opportunities.
d. Maintaining Security and Compliance
With increasing regulatory pressure and security threats, ensuring that DevOps practices remain secure and compliant while scaling is critical.
Example: A healthcare provider faced a data breach after an insecure configuration in an automated CI/CD pipeline exposed patient records.
2. Best Practices for Scaling DevOps

a. Standardize Tooling and Processes
Establishing a consistent set of tools and workflows across all teams reduces complexity and improves efficiency.
- Implement a single CI/CD pipeline tool (e.g., Jenkins, GitLab) for consistent deployment processes.
- Use infrastructure as code (IaC) tools like Terraform or Ansible to automate infrastructure provisioning and ensure consistency.
- Create a central repository for configuration files and deployment scripts to reduce variation across teams.
Example: Spotify developed its “Backstage” platform to unify developer tools and processes, reducing onboarding time and improving system reliability.
b. Adopt a “Platform Engineering” Approach
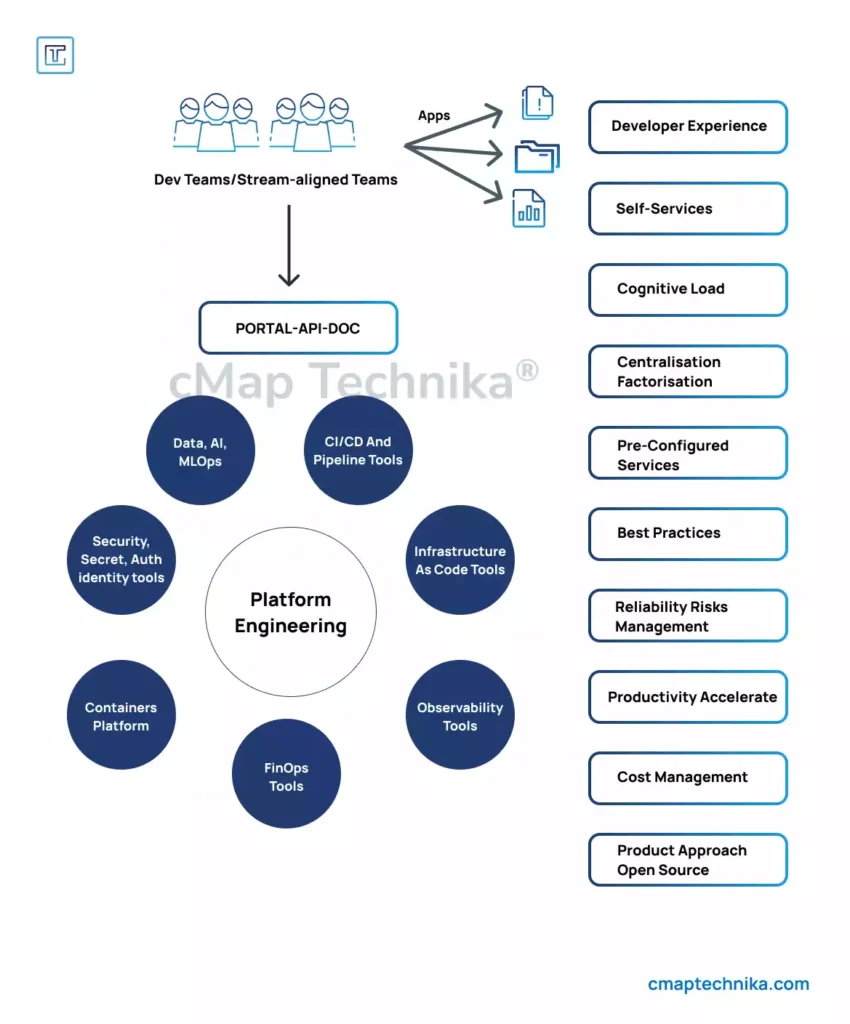
Develop a self-service internal platform where development teams can access standardized tools and infrastructure components.
- Build reusable infrastructure templates for consistent deployment.
- Create developer portals to simplify service discovery and integration.
Example: Netflix created a developer platform that allows teams to provision infrastructure and deploy services with minimal manual intervention, accelerating release cycles.
c. Implement Automated Monitoring and Feedback Loops
Automation should extend beyond deployment to include monitoring and incident response.
- Use monitoring tools (e.g., Prometheus, Datadog) to track performance in real time.
- Automate root cause analysis to diagnose issues quickly.
- Establish alerting systems to notify teams of potential failures before they impact users.
Example: Amazon relies on automated monitoring and anomaly detection to identify and address issues in real time, minimizing customer disruptions.
d. Introduce Progressive Delivery Techniques
To minimize risk and improve user experience, deploy changes incrementally and monitor outcomes before full rollout.
- Use feature flags to enable or disable features without redeploying code.
- Implement canary releases to test new features with a subset of users before full deployment.
Example: Google’s Kubernetes platform enables controlled rollouts and rollback capabilities, reducing the impact of failed updates.
e. Embed Security into the DevOps Pipeline (DevSecOps)
Security should be integrated at every stage of the development lifecycle.
- Automate security scans and vulnerability assessments in CI/CD pipelines.
- Use policy-as-code to enforce security standards and compliance requirements.
Example: Capital One adopted DevSecOps by integrating automated security checks into its pipelines, reducing security vulnerabilities by over 30%.
f. Empower Teams Through a “You Build It, You Run It” Model
Give development teams full responsibility for the lifecycle of their code, from development to deployment and operations.
- Assign operational ownership to developers to ensure accountability.
- Provide training on monitoring, incident management, and performance optimization.
Example: Amazon’s “You Build It, You Run It” model ensures that developers are responsible for maintaining and fixing their code in production, driving higher quality and faster response times.
3. Measuring Success in Scaled DevOps
To ensure continuous improvement and alignment with business objectives, establish clear metrics and performance indicators:
- Deployment Frequency – Measure how often code is deployed to production.
- Change Failure Rate – Track the percentage of failed deployments to identify quality issues.
- Mean Time to Recovery (MTTR) – Measure how quickly teams resolve incidents.
- Defect Escape Rate – Track how many defects reach production.
- Application Availability and Reliability – Monitor system uptime and performance stability.
Example: Google’s Site Reliability Engineering (SRE) team measures error budgets to balance release velocity and system stability.
4. Case Study: Scaling DevOps at LinkedIn
LinkedIn’s transition to a DevOps model provides a blueprint for large-scale implementation.
- Challenge: LinkedIn struggled with inconsistent deployment processes and slow release cycles due to fragmented tooling.
- Solution: The company standardized on Kubernetes for container orchestration and Jenkins for CI/CD pipelines.
- Outcome: Deployment frequency increased by over 50%, and production issues decreased by 30%.
- Key Takeaway: Consistency and automation were key to scaling LinkedIn’s DevOps operations effectively.
5. Future Trends in Scaled DevOps
As enterprises continue to scale DevOps, several trends are shaping the future:
- AI and Machine Learning in DevOps: Predictive analytics and AI-driven automation will enhance performance and reliability.
- GitOps: Using Git as the single source of truth for infrastructure and application state will simplify automation and scaling.
- Serverless Architectures: Abstracting infrastructure management will allow teams to focus on code rather than infrastructure maintenance.
Conclusion
Scaling DevOps in large enterprises requires a strategic approach that combines automation, standardization, and a culture of collaboration. By adopting platform engineering, progressive delivery, and DevSecOps practices, organizations can achieve faster release cycles, improved reliability, and enhanced security. Measuring performance through key metrics ensures that teams remain aligned with business objectives and continue to drive innovation.

Author: Jennifer Wilson
Hey! This is Jennifer


